问题起源
背景是发现盘古首页中,很多 js 的 sourcemap 对应关系不对,导致不方便 debug 问题。
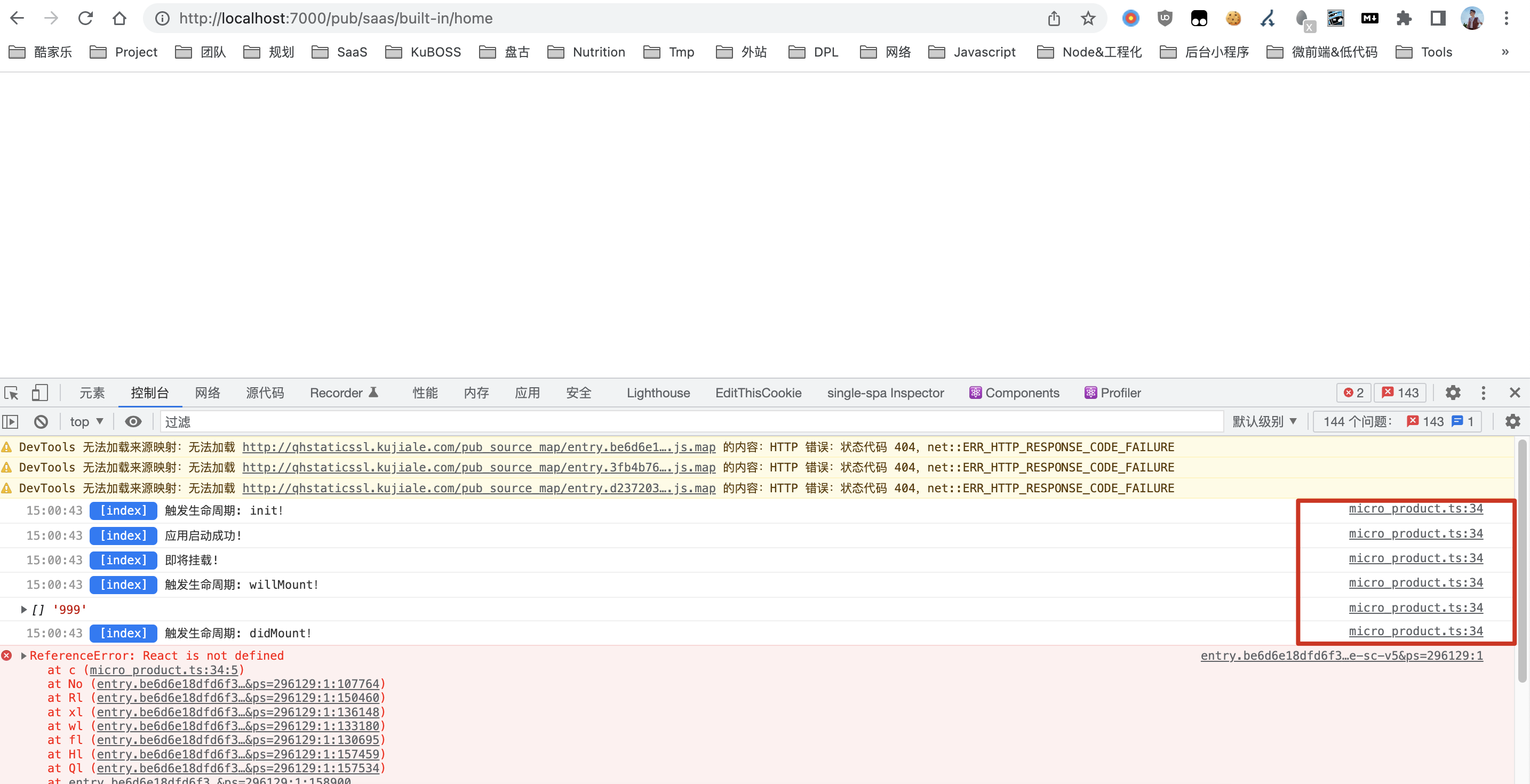
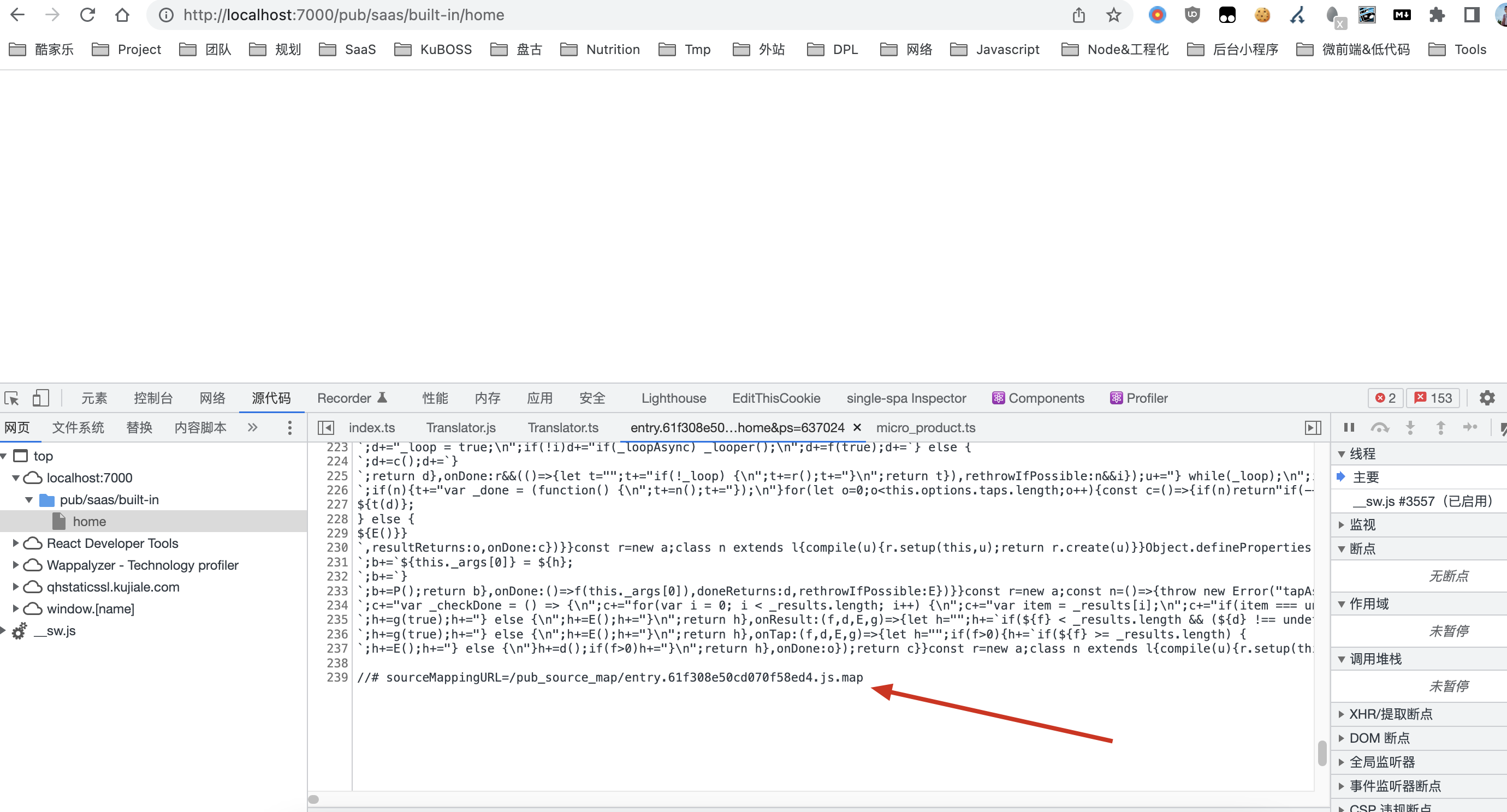
- 上图中以 /pub_source_map/ 开头的 mapping 文件内容是错误的,并不和源文件对应。
- 问题原因后来找到并修复了,是因为 repo 接入 esbuild 太早,当时的 sourcemap-loader 配置有问题。
接下来进一步拓展一下 sourcemap 相关内容。
Sourcemap
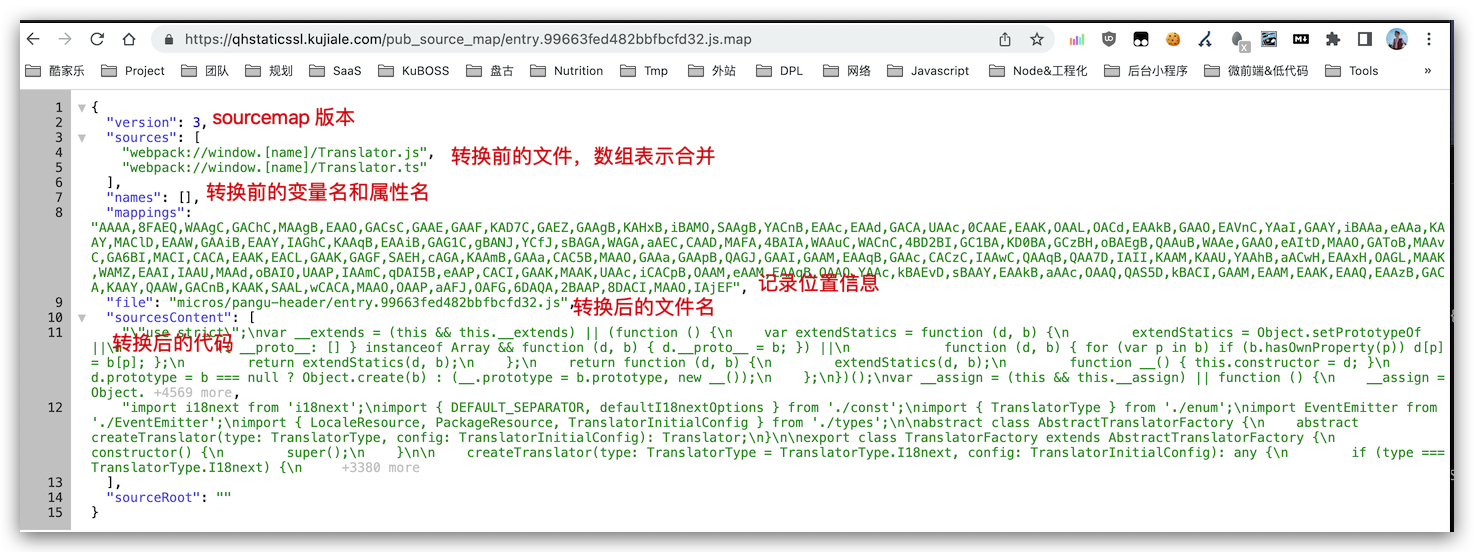
Sourcemap 解决了源代码被压缩和混淆,导致 debug 困难的问题。它包含了源代码和生产代码的映射。主要应用在前端监控、报错排查。 2011年,诞生 v3 版本标准(Source Map Revision 3 Proposal),相对前两个版本进一步缩小了 map 文件体积。 一个 sourcemap 文件内容大概长这样:
问题1:sourcemap 是在哪里配置生成的?
webpack 里可以配置 sourcemap 的生成类型,devTools 的可选配置项很多,可以在构建速度和调试方便性取一个平衡。这里不再赘述。
问题2:浏览器怎么知道源文件和 sourcemap 文件的对应关系?
一般在文件最后会加一句://# sourceMappingURL=xxx.js.map,表明该源文件对应的 map 文件地址。除了这种常规方式之外,也可以在 response header 的 SourceMap: <url> 字段来表明。
注:source map 只有在打开 dev tools 的情况下才会开始下载。
问题3: sourcemap 是如何对应到源代码的?
mappings 的内容是 Base64 VLQ 的编码表示的,尽可能减小 map 文件体积。
- 分号:生成的文件的每一行用分号(;)分隔,一个分号代表转换后源码的一行
- 逗号,位置对应,每一段用逗号(,)分隔,一个逗号对应转换后源码的一个位置
- 英文字母,每一段由1,4或5块可变长度的字段组成,记录原始代码的位置信息。 详细的编码规则和示例网上有很多介绍,不再赘述。例如:何为SourceMap?讲讲SourceMap食用姿势
问题4:pub 打包出来的 js 其实并没有 //# sourceMappingURL 这行,那么是怎么映射的呢?
pub 基于 serviceworker 为所有带有 “pn” 和 “ps” 参数的 js 文件添加了 sourcemap 配置,开发者调试时浏览器能自动映射到源文件。 sit 和 prod 是两个不同的 sw 文件,所以 prod 不会自动添加 sourcemap,防止源码泄露。
注:
- tobdev 环境是不会被自动注入 sourcemap 的,因为该环境不支持 https,也就无法走 service worker 逻辑。
- 目前 pub 默认都会打出 sourcemap(pub devtool 配置 默认为 ‘hidden-source-map’,不为源文件增加注释),现在也不用再手动加 sourcemap: true 构建参数。
具体实现: pub 通过 serviceworker 拦截 fetch 事件,注入 sourcemap 注释,查看核心代码
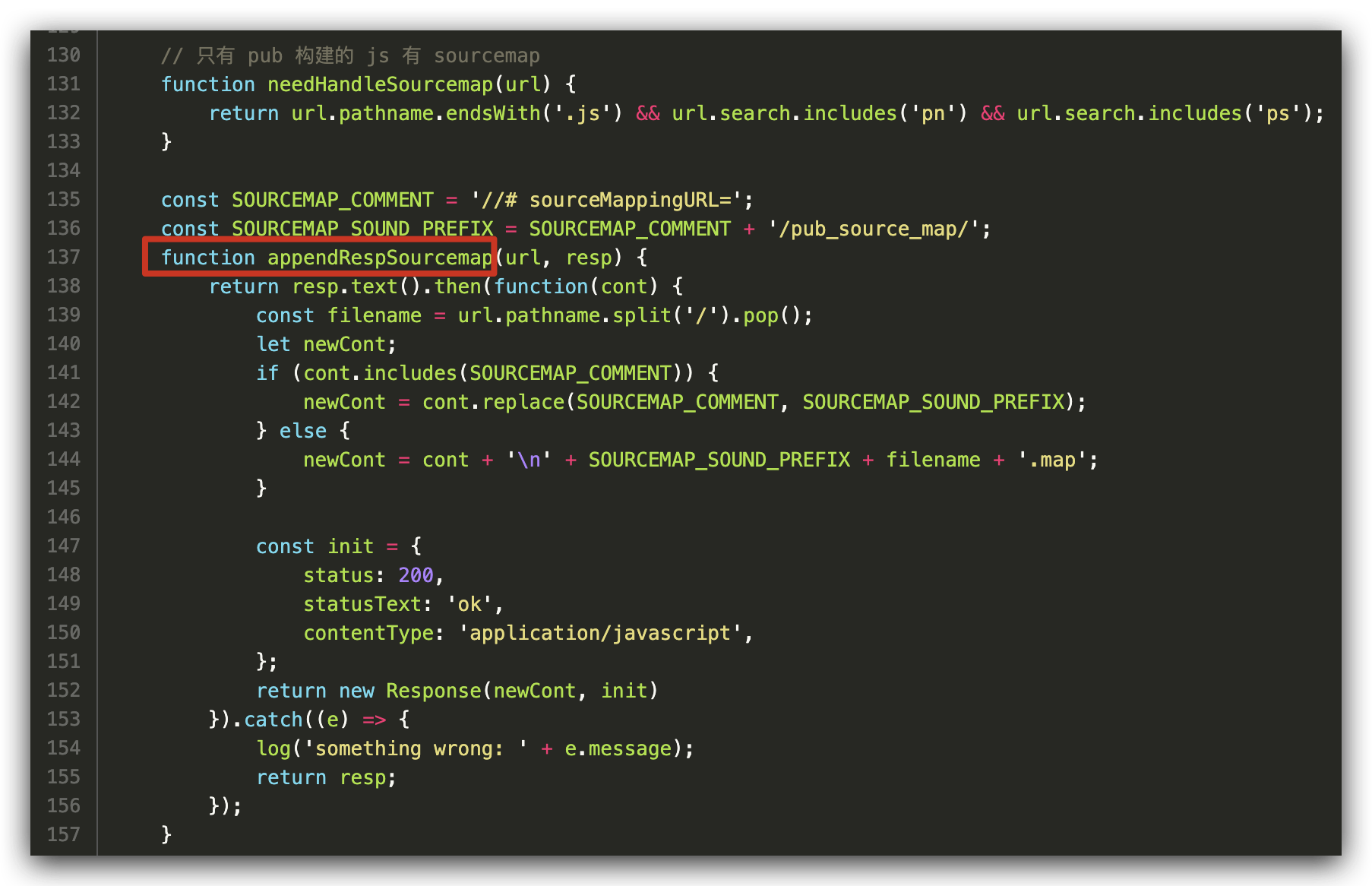
问题5:那线上代码如何用 sourcemap 调试,又防止源码被别人查看呢?
线上想源码调试的话,可以按照 此规则对应关系(仅内网访问) 手动在 devtools 里加 sourcemap。 这个方案还不够完美,我给 pub 提了改进建议,做成小工具,更方便且规避代码泄露风险。
为什么把这块逻辑放在 service worker 里做?无意中在代码里还发现了云设计工具相关的内容(GitLab),他们又基于 service worker 干了啥呢?
Service Worker
Service workers 可以拦截页面中的网络资源请求,当你发送请求的时候,会从本地缓存提供资源。在构建 PWA 离线应用时很有用,也常用于预获取用户可能用到的资源,或后台数据同步。以下简称 sw。
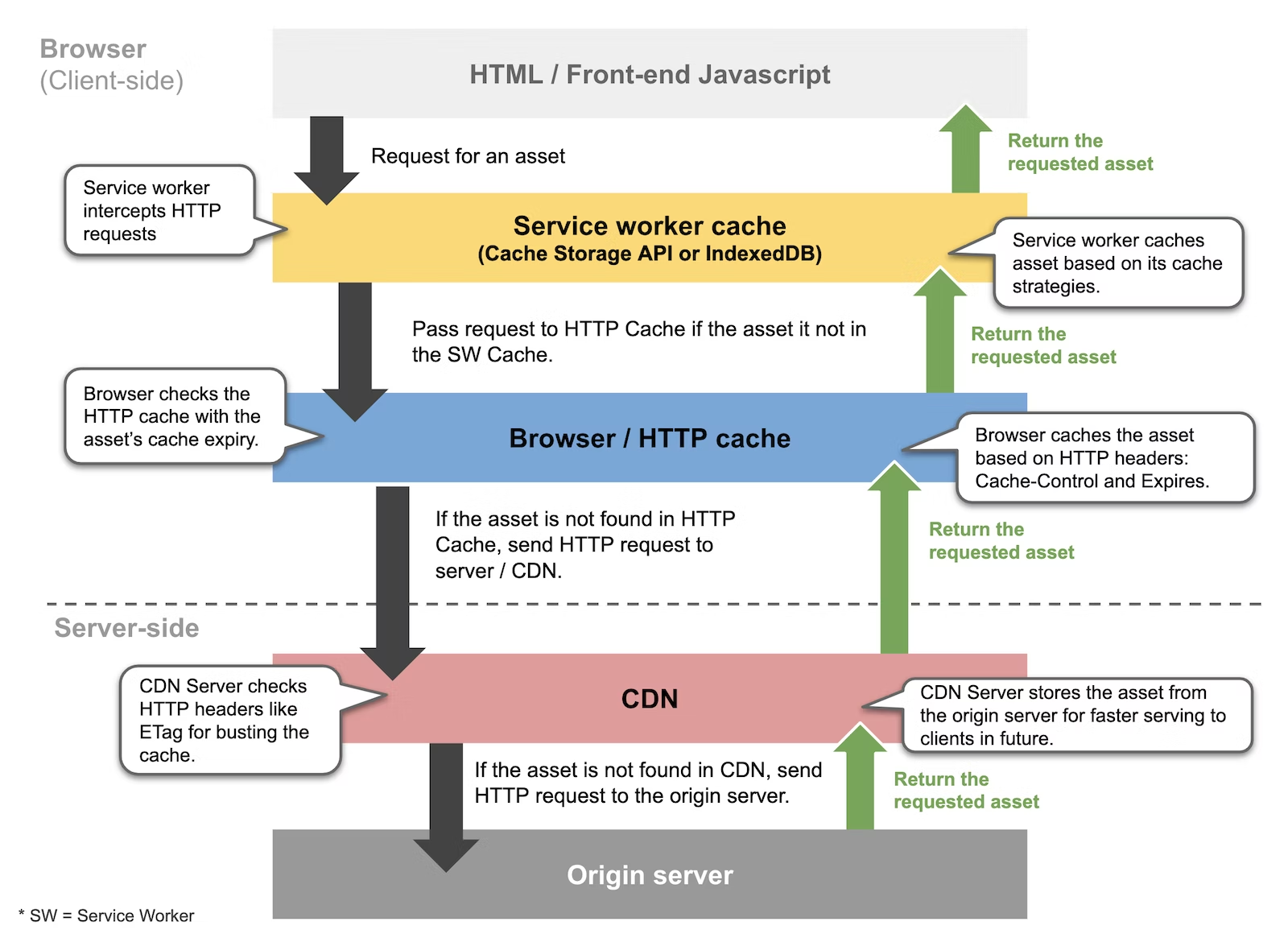
在我们的 sw 脚本中,云设计工具相关的主要逻辑:在 service worker install 事件中, 把白名单里的微应用 fetch 过来,把里面的 js src 解析出来然后 cache.addAll 放在 cache storage 里。
可以在 chrome 的 devtools 里看到已缓存的内容,以及浏览器 cache storage 给我们预留的空间:
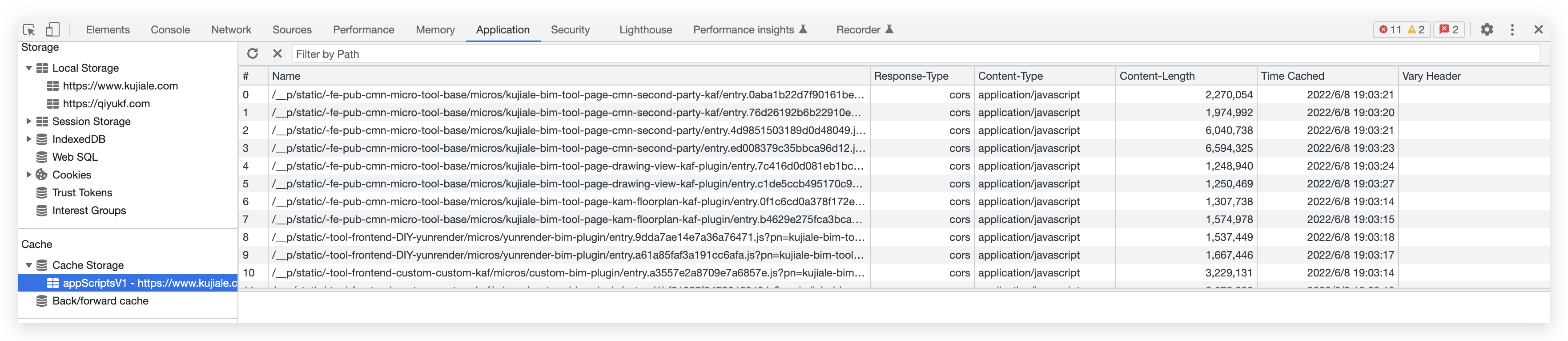
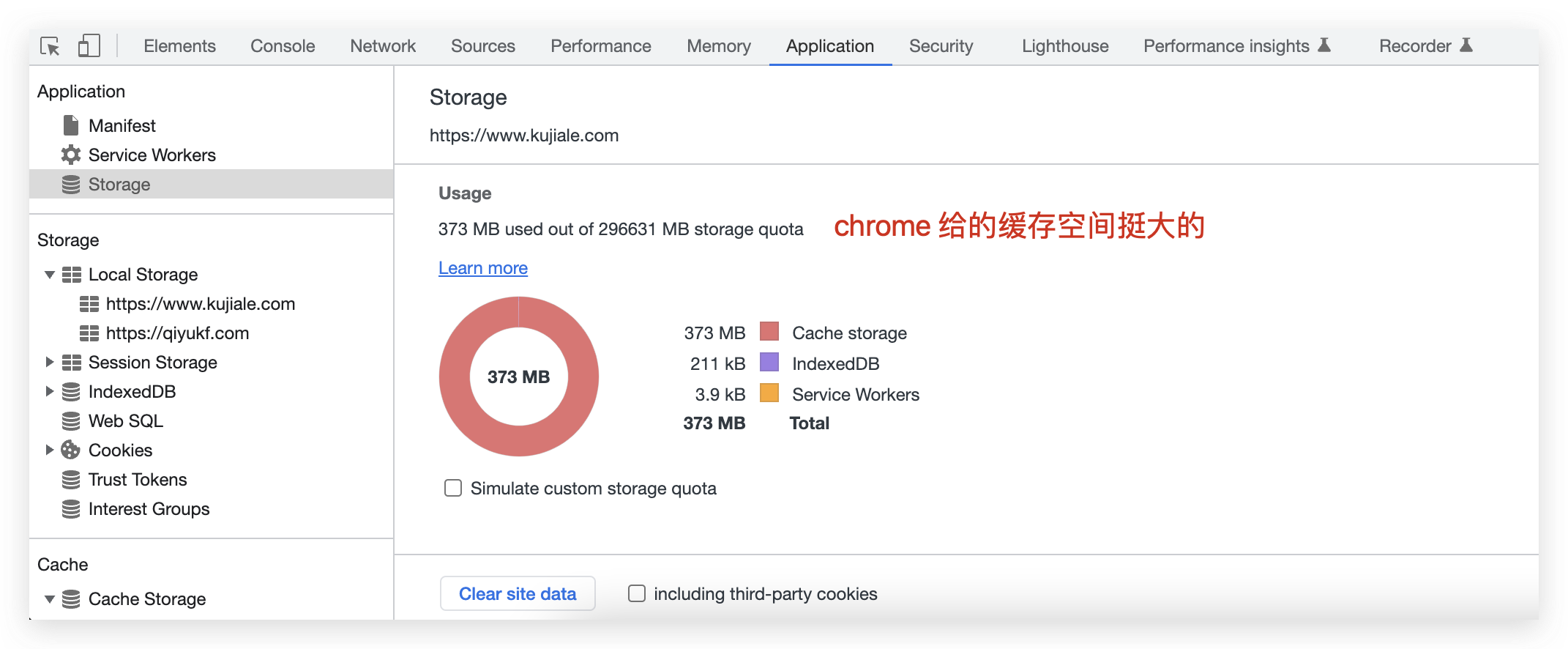
- localstorage 跟 service worker 的 cache 工作原理很类似,但是它是同步的,所以不允许在 service workers 内使用。sw 设计为完全异步。
- service worker 运行在 worker 上下文,不能访问 DOM
- 如果一个页面有多个 sw 脚本共存会有污染,可能需要先 unregister。目前酷家乐全站只有一个根路径下的 sw。
问题:为啥云设计工具要把 js 脚本缓存在 cache storage 里??
这里的主要目的不是为了离线缓存,而是 触发 V8 主动 code caching,避免二次编译。
V8 Code Caching
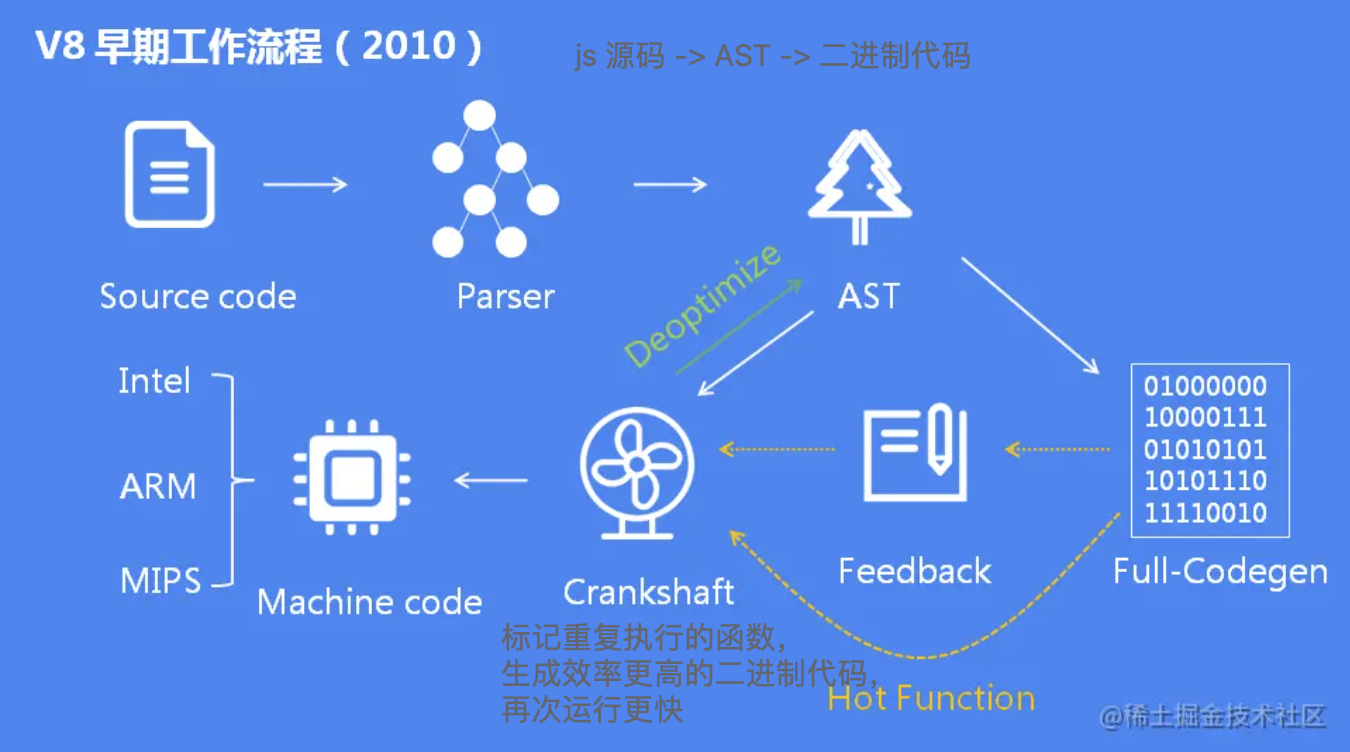
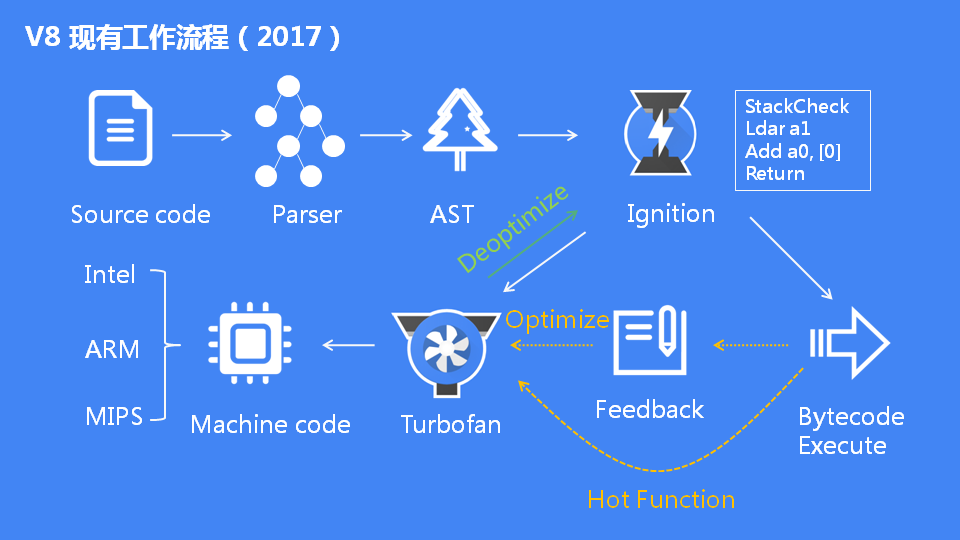
啥是 Code Caching? 首先回顾一下 V8 的运行机制。当前 V8 执行 JavaScript 流程图:
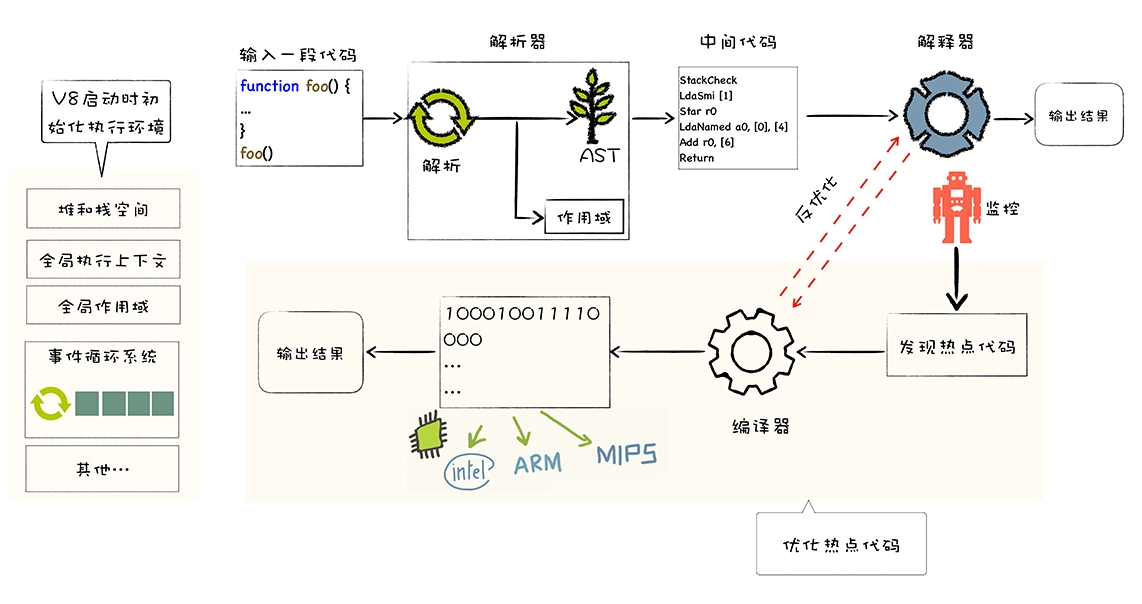
V8 使用 JIT (Just in time compilation) 来执行 JavaScript 代码,也就是说在 JS 脚本执行之前,必须对其进行解析和编译,这一步的开销是较大的。
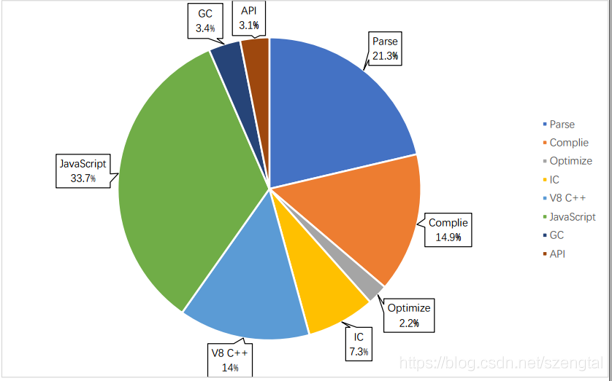
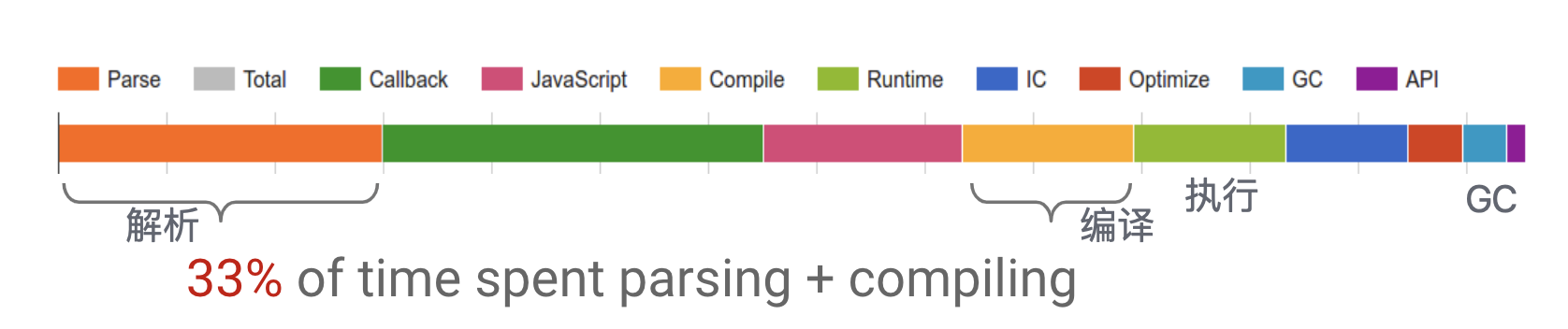
如图(来源网络)解析和编译 js 所花费的时间占到了整个 V8 运行周期总时间的三分之一。
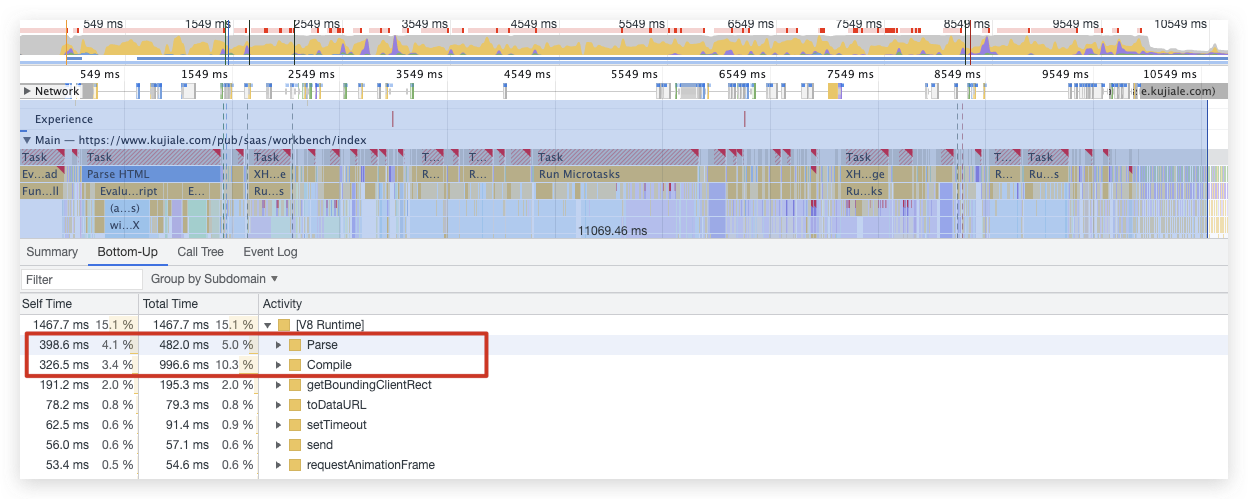
盘古首页中 V8 的 parse 和 compile(更具体的 V8 分析需用 trace 工具):
code caching 原理
V8 code caching 的原理(官博解释:Code caching · V8)是:
- 第一次运行 JS 脚本的时候同时会生成该 JS 脚本的字节码缓存,并保存在本地磁盘,
- 第二次再运行同一个脚本的时候,V8 可以利用第一次保存的字节码缓存重建 Compile 结果,这样就不需要重新编译。
- 这样第二次执行这个脚本将会更快。
简单来说,使用了code caching 后,当 JS 第一次被编译后,将生成的代码序列化后存储在磁盘上,后续再次加载时,会优先读取磁盘中的缓存,直接反序列化后执行,避免 JS 被从头编译造成重复开销。
V8 中的缓存:
目前在V8中实现了两个级别的缓存,每个 V8 实例的内存缓存(Isolate 缓存,不同标签页无法共享)和代码序列化后的磁盘缓存。
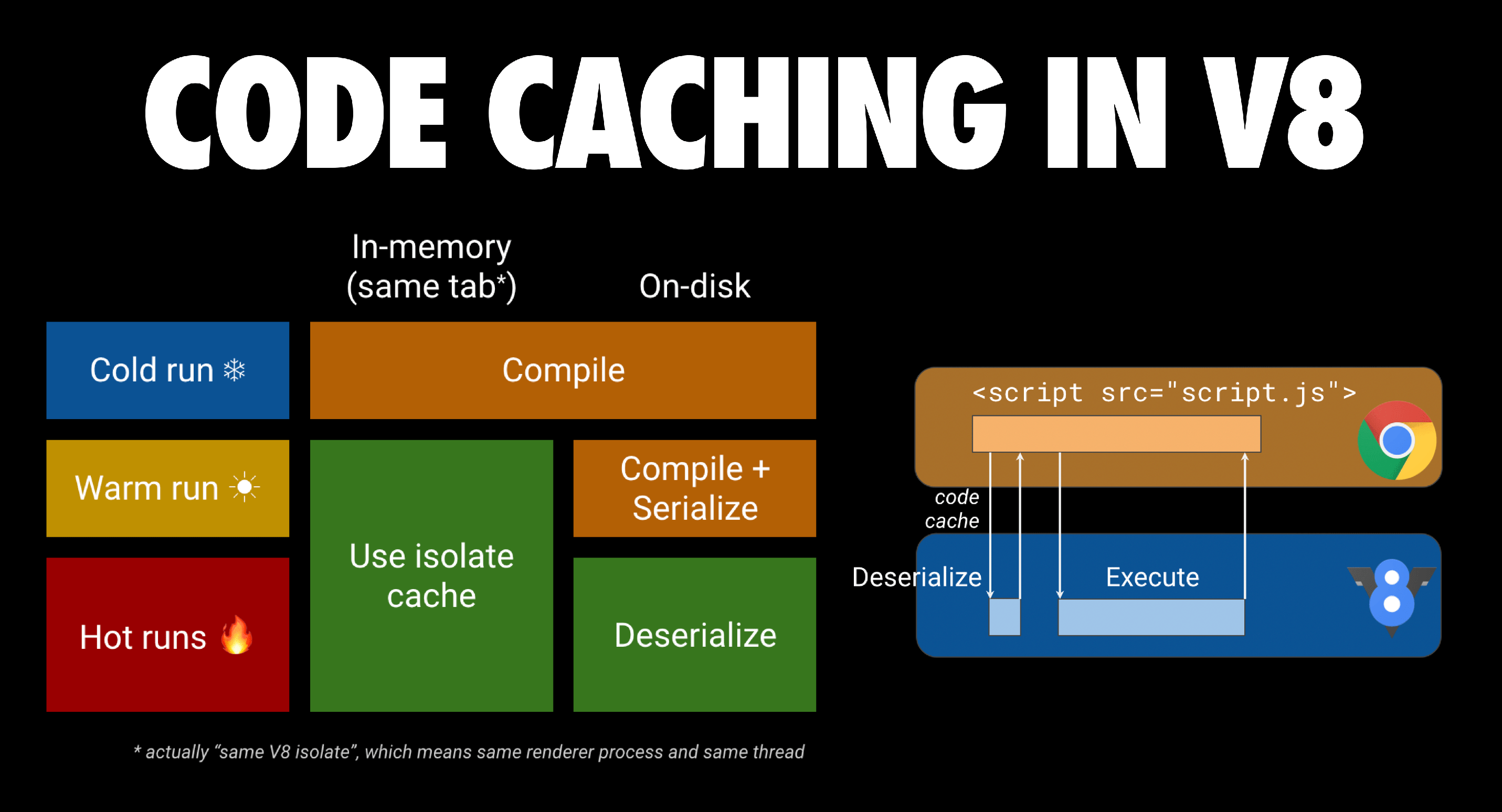
code caching 在 V8 内的具体行为:
- Cold run(第1 次请求 js 文件):Chrome 会下载它并将其交给 V8 进行编译,并将文件存储在浏览器的磁盘缓存中;
- Warm run (第 2 次):Chrome 会从浏览器缓存中获取该文件,并再次将其交给 V8 进行编译。然而这一次,编译后的代码被 序列化,并作为元数据附加到缓存的脚本文件中。
- Hot run(第3 次):Chrome 从缓存中获取文件 和文件的元数据,并将两者交给 V8。V8 对元数据进行反序列化,可以跳过编译。
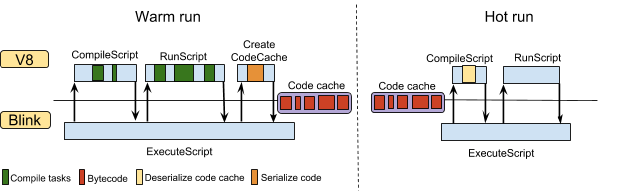
参考改进的 code caching:Improved code caching · V8,中文译文:V8 6.6 进一步改进缓存性能 - 知乎
Chrome 从 42 开始引入 code caching(ref:Chromium Blog: New JavaScript techniques for rapid page loads),chrome 66 进行了改进。从原来只缓存 IIFE,优化为可以为整个文件缓存,尽可能缓存更多内容。
问题1:为什么在 warm run 阶段我们才会生成code cache呢?
- 因为实际上很多文件我们确实只会遇见一次,如果每一份文件都要执行序列化并缓存会造成很大的浪费。
- 因此,只有在 72h 内至少看到 两次相同 的脚本时,Chrome 才会做 code caching。
- 另外,1KB 以内的小文件不会被 code cache,所以大于 1KB 的脚本就不应该用内联脚本,否则无法被缓存。
问题 2:如何主动触发 Code caching?
Code caching for JavaScript developers · V8 官方博客提到了一些最佳实践。
- 其中一种方式是把 js 缓存在 service worker 的 Cache Storage 里。当资源被放入 service worker 中时,会生成完整的代码缓存(编译所有内容)。具体操作:在 install 事件里,利用 cache API 把需要被缓存的 js 加到 cache 里。V8 会直接把所有代码进行编译做 code caching。
- 另外还可以包装成 IIFE(这种方式可能滥用官方不推荐,原因是会 parse 可能不被运行的函数而降低冷启动性能并且内存占用增大,惰性解析优化也会失效。 于是这里解答了,“为什么云设计工具把公共 js 放在了 service worker 缓存里”的问题。
问题 3:为啥包装成 IIFE 会更快呢?
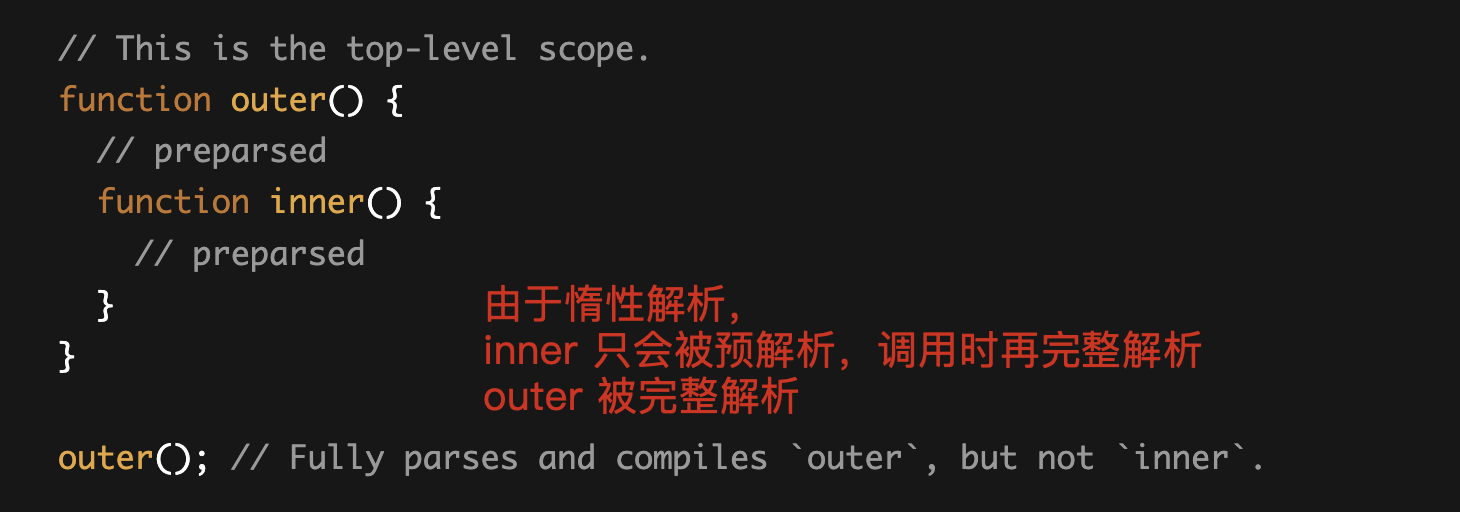
比如 GitHub - nolanlawson/optimize-js: Optimize a JS file for faster parsing (UNMAINTAINED) optimize-js 这个包曾用于把普通函数变成 IIFE,后来不维护了。 IIFE 更快的原理是非 IIFE 会先被预解析然后再被完整解析,共被解析两次。而 IIFE 可以跳过预解析直接完整解析。 预解析只会做语法分析和错误检查,不会生成 AST,关于预解析参考 Blazingly fast parsing, part 2: lazy parsing · V8
问题 4:为什么工具中依赖的 pub 微应用默认没有被 code caching,而要放在 service worker 里,来自佚名的分析 code caching没有生效的原因 (已解决)
- 基于 v8 的 code caching 的 策略——一个 script 只会 cache自身执行期间被编译过(一般只有执行之前才会compile code)的 function,所以公共包微应用的绝大部分函数都不会被cache。
- 这些代码在接下里被业务微应用调用时,会在调用前被compile一遍,这可能是目前我们观察到compile code时间占init时间一半的部分原因。
问题 5:Node.js 中如何主动 code caching?
如果是在Node 中,可以用 v8-compile-cache 这个包。原理参考 为什么利用 vm.Script 可以实现 Node.js 中的 code cache | 梅旭光的个人博客
问题 6: code caching 效果如何?
网上有份 code caching 前后效果对比:
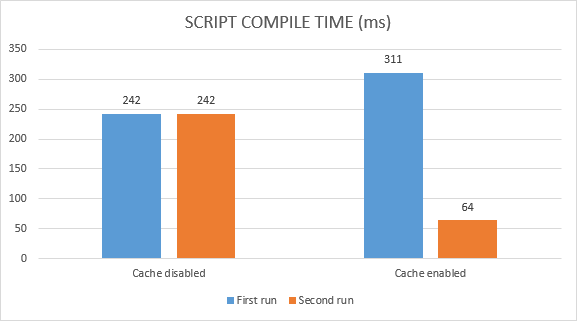
从 CF 中看到的云设计工具的优化结果来看,非初次加载的时间能够直接降低近50%, (5s -> 3s)。另外 bundle最佳code cache策略,应用加载速度提升 28%
问题 7:主动触发 code caching 的应用场景有哪些:
- 工具类单页面产品加载性能优化,如果 js 脚本多,编译花费大量时间,可以把变动不频繁的 js 主动做 code caching,提升再次执行的速度。
- FaaS 场景下减少 node 的启动时间。自动缩扩容是 K8S 的重要特性,面对忽然到来的大流量,需要在极短的时间对函数进行扩容并可以正常相应请求,这就对 Node.js 函数的启动时间有了较高的要求,公共模块在构建阶段提前编译成字节码打包到镜像中直接使用,来提升 faas 函数的启动时间。 (淘宝称有 40% 的速度提升)。 淘系前端团队
- VS Code 启动性能优化,淘系前端团队
题外话: V8 字节码的前世今生
字节码是一种中间码,它比机器码更抽象。
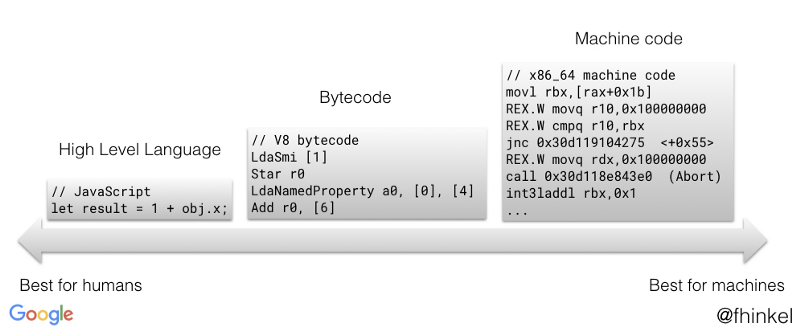
采用字节码的优点:
- 不针对特定 CPU架构
- 比原始的高级语言转换成机器语言更快
- 比如 java 早期口号 Compile Once,Run anywhere(一次编译到处运行),编译为 .class的字节码文件,再通过 JVM 转为机器码
V8 早期没有生成字节码,直接生成机器码,比较激进(图片 from JavaScript 引擎 V8 执行流程概述):
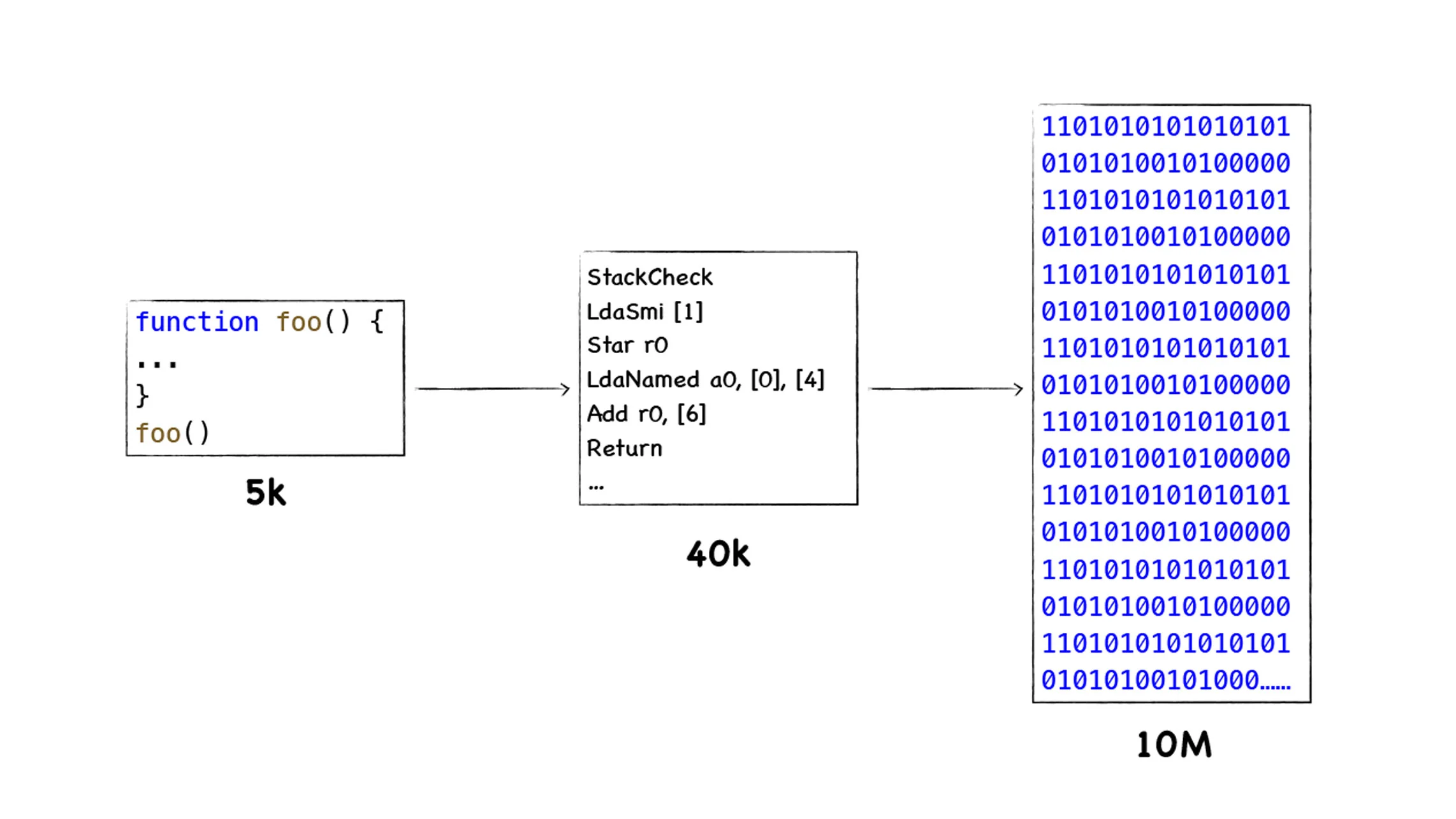
而为什么现在 V8 字节码又回来了:
- 内存占用可以更小,不用把机器码缓存下来。
- 降低代码复杂度。编译器不必适配不同 CPU 架构
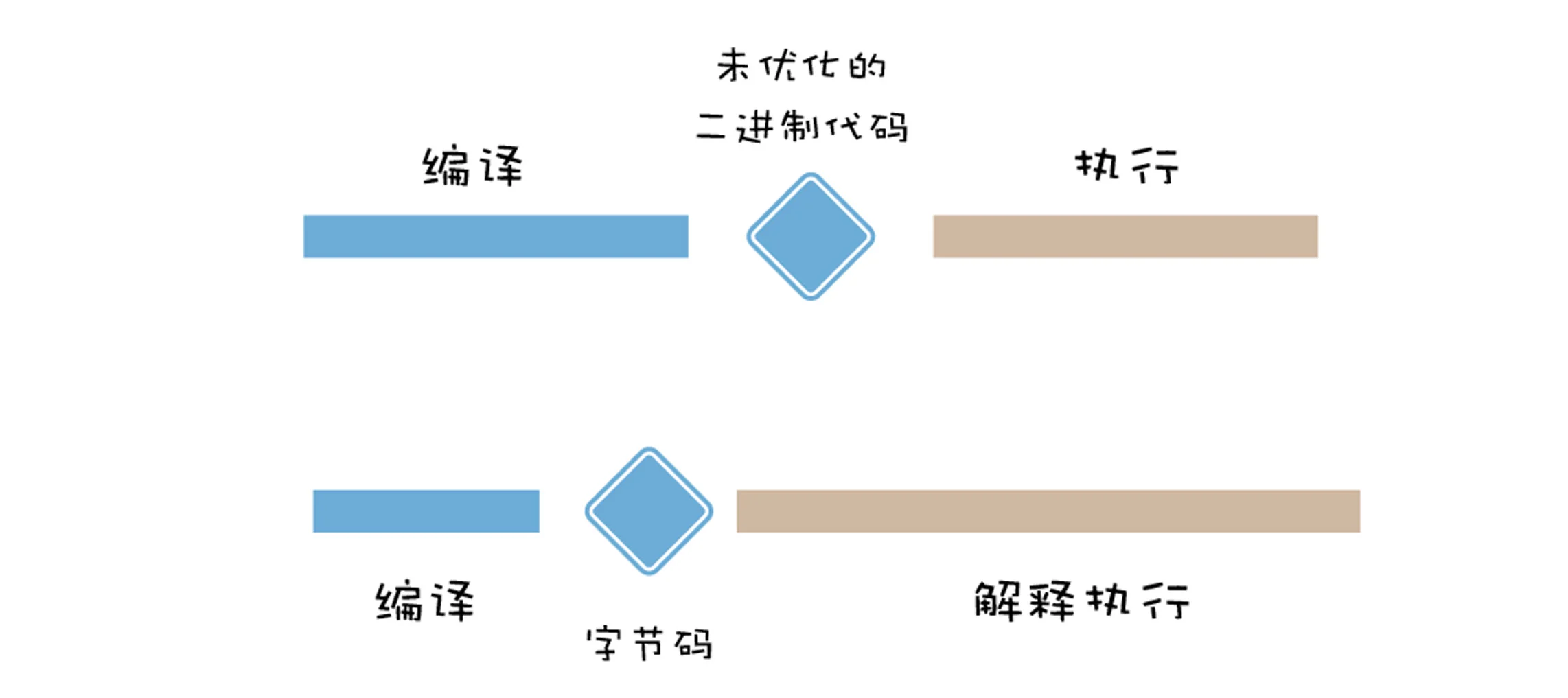
虽然采用字节码在执行速度上稍慢于机器代码,但是整体上权衡利弊,采用字节码也许是最优解。因为采用字节码除了降低内存之外,还提升了代码的启动速度,并降低了代码的复杂度,而牺牲的仅仅是一点执行效率。
反观我们日常工作中,
- 技术选型其实都需要在体验、效率、维护性、工程架构复杂度中取得平衡。没有绝对最好的,只有最合适的。
- 初期选型错了也不要紧,重要的是及时调整并不断改进!
其他最佳实践:
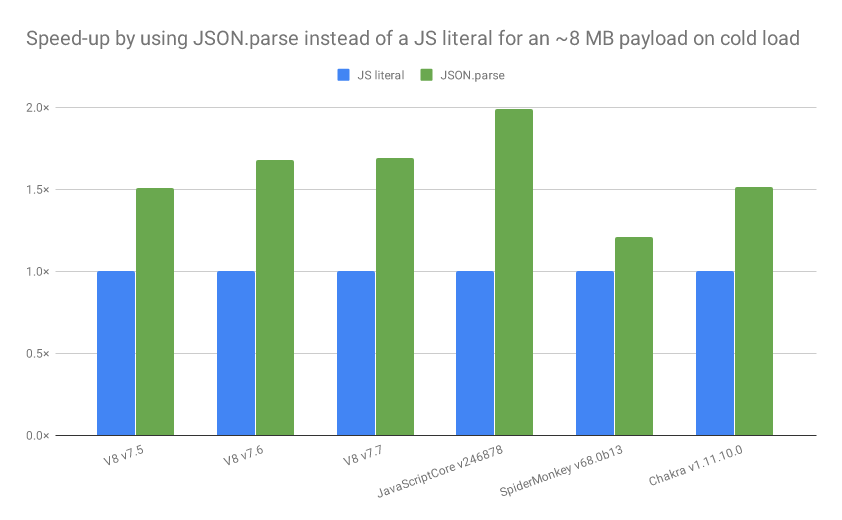
The cost of JavaScript in 2019 · V8 提到,JSON 的解析效率比 js 高(1 ~ 2 倍),并且不会被解析两次。如果对象大于 10KB,应考虑用 JSON。